
훈훈훈
Spring boot :: Transaction default isolation level 은 어떻게 결정이 될까 본문
Spring boot :: Transaction default isolation level 은 어떻게 결정이 될까
훈훈훈 2022. 3. 13. 17:18Introduction
블로그 포스팅 스터디에서 스터디원과 Spring default isolation level 이 어떻게 결정 되는지 토론을 하게 되었다.
토론 도중에 스터디원분이 관련 StackOverFlow 글을 찾고 공유해주셨는데, 글 내용은 MySQL connectror/J 는 default isolation level 로 READ_COMMITTED 를 제공한다는 것이다.
실제로 코드 레벨에서 살펴보니 진짜 READ_COMMITTED 로 제공이 되고 있었다.

내가 알던 내용은 MySQL 은 storage engine 으로 innoDB 를 사용하는 경우 default isolation level 로 REPEATABLE_READ 를 제공한다는 것이다.
그렇기 때문에 MySQL connector/J 도 당연히 REPEATABLE_READ 로 제공이 될 줄 알았는데 결과는 꽤나 놀라웠다.
그와 반대로 MariaDB connector 는 REPEATABLE_READ 로 제공한다.
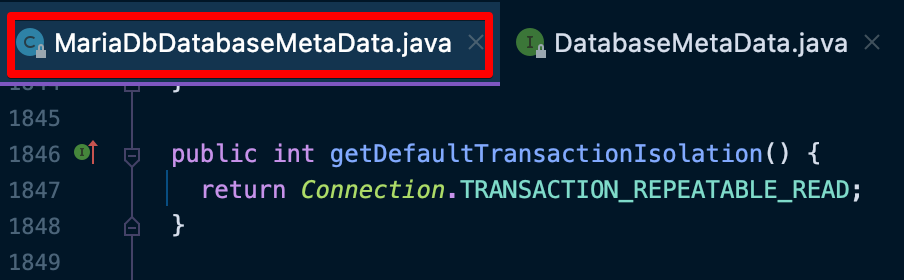
테스트로 스프링 애플리케이션에서 jdbc url 을 MySQL 로 연결하였을 때 isolcation level 값을 확인해보았다.
그 결과 REPEATABLE_READ 가 나왔다.
왜 이런 결과가 나오는지 궁금하여 스프링 코드를 따라가 보면서 어떻게 default isolation level 을 결정하는지 찾아보게 되었고, 그 과정을 정리해보려고 한다.
결론부터 먼저 말하자면 스프링에서 MySQL 을 사용하는 경우 REPEATABLE_READ 로 제공이 된다.
(실제로는 RDBMS 와 커넥션을 맺고 정보를 가져옴)
이번 계기로 어설프게 대충 판단을 하면 안되는 것을 다시 한 번 느꼈다. 🥲
@Transactional test
일단 스프링에서 어떻게 동작하는지 아래 코드로 테스트 해보았다.
(해당 코드는 예전에 예제로 만든 프로젝트이며, 전체 코드는 Github 에서 확인할 수 있다.)
@Service
@RequiredArgsConstructor
public class AccountService {
private final AccountRepository accountRepository;
private final PasswordEncoder passwordEncoder;
private final DataSource dataSource;
@Transactional
public AccountDto createAccount(@Valid final SignUpDto accountDto) throws SQLException {
final Account existAccount = accountRepository.findAccountByEmail(accountDto.getEmail()).orElse(null);
if (existAccount != null) {
throw new IllegalArgumentException("duplicated");
}
final Account account = Account.builder()
.name(accountDto.getName())
.email(accountDto.getEmail())
.password(passwordEncoder.encode(accountDto.getPassword()))
.build();
System.out.println("------------------------------------");
System.out.println(dataSource.getConnection().getTransactionIsolation());
System.out.println("------------------------------------");
return AccountDto.of(accountRepository.save(account));
}
}간단하게 @Transactional 이 선언 된 메소드에서 transaction isolataion level 을 조회해보았다.

isolation level = 4로 나오고 해당 번호는 REPEATABLE_READ 를 뜻한다.
해당 값이 의미하는 바는 Connection interface 에서 확인할 수 있다.

Code Analysis
이제 스프링 코드를 디버깅하면서 어떻게 동작하는지 살펴보자.
Spring 애플리케이션을 실행시키면 NonRegisteringDriver 클래스의 connect 메소드는 jdbc url 을 파라미터로 전달 받은 후에 Connection 객체를 생성 후에 리턴을 하게 된다.

생성이 되는 Connection 객체는 com.mysql.cj.jdbc.ConnectionImpl 클래스이며 해당 객체가 생성이 되면서 isolation level 도 결정한다.
이제 ConnectionImpl 객체가 생성 되는 과정을 살펴보자
ConnectionImpl 클래스의 getInstance 메소드는 정말 단순하다.
해당 클래스의 생성자를 호출해서 리턴하는 역할만 한다.

그 다음으로 ConnectionImpl 클래스 생성자에는 여러 로직들이 들어있어 다소 코드 라인이 좀 길다.
그래서 전체 코드는 첨부하지 않고 부분 부분 캡쳐해서 넣었다.
먼저 살펴볼 내용은 위에 서론에서 언급한 내용이다.

해당 라인에서 MySQL Connector/J 에서 정의한 메타 데이터를 가져오게 되는데, 여기에서는 코드에서 정의한 default isolation level 로 초기화가 된다.
해당 라인을 실행시켰을 때 디버깅한 값을 확인해보면 isolation level = 2(READ_COMMITTED) 로 세팅된 것을 볼 수 있다.

그 다음에는 몇 라인 아래에 있는 createNewIO 메서드를 확인해보자
해당 메서드 호출 후에 isolation level = 4 (REPEATABLE_READ) 로 세팅이 된다.

createNewIO 메소드르 이후 아래 흐름으로 메소드 Call 이 발생한다.

마지막으로 checkTransactionIsolationLevel 메소드에서 MySQL 서버와 커넥션을 맺고 isolataion level 을 가져오게 된다.
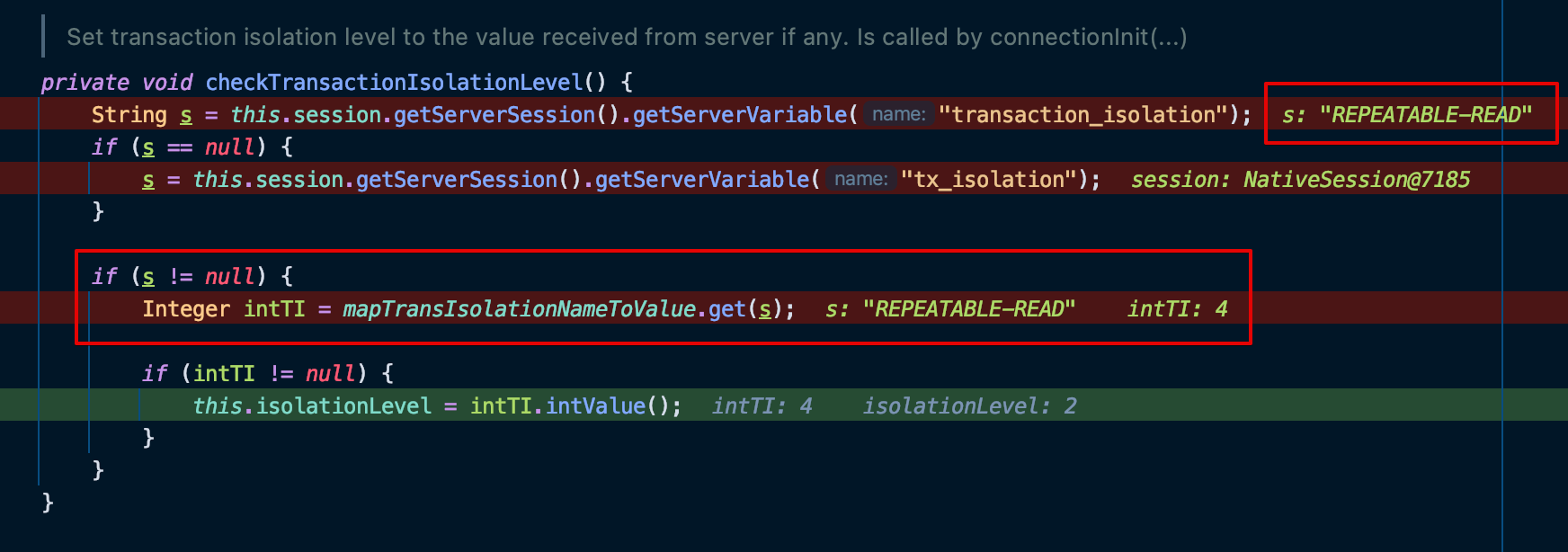
이후 처리하는 과정을 더 있는 것 같지만, 목적은 이미 달성했기에 이정도에서 마무리하려고 한다.
'Spring Framework > 개념' 카테고리의 다른 글
| Spring Data :: Spring Data Elasticsearch refresh policy 정리 (0) | 2022.01.31 |
|---|---|
| Spring Data :: Spring Data Elasticsearch _class 필드 자동 생성 비활성화 (0) | 2021.11.27 |
| Spring Data :: Spring Data Elasticsearch rollover index 정리 (1) | 2021.11.26 |
| Spring Cloud :: Spring cloud sleuth 정리 (0) | 2021.11.13 |
| Spring boot :: Caffeine cache 정리 (2) | 2021.10.31 |



